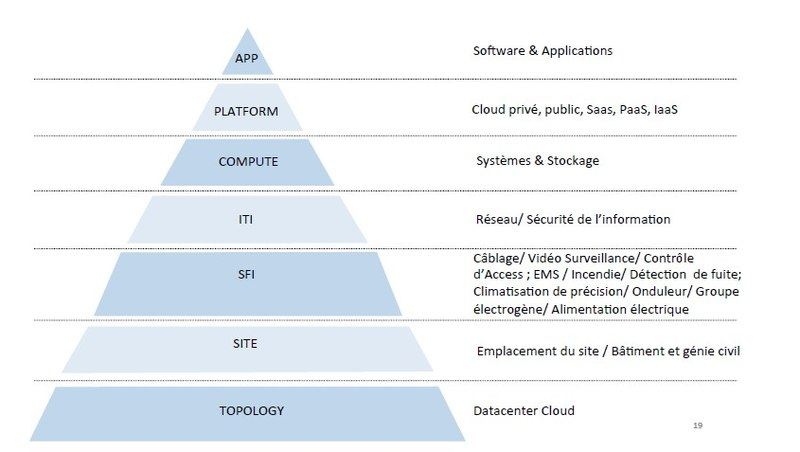
Modèle en couche-Résumé
assure l’accès aux services de façon optimale, pour offrir une haute disponibilité, l’équilibrage de la charge réseau comprend des fonctionnalités intégrées qui peuvent automatiquement :
Deux moyens complémentaires sont utilisés pour améliorer la disponibilité :
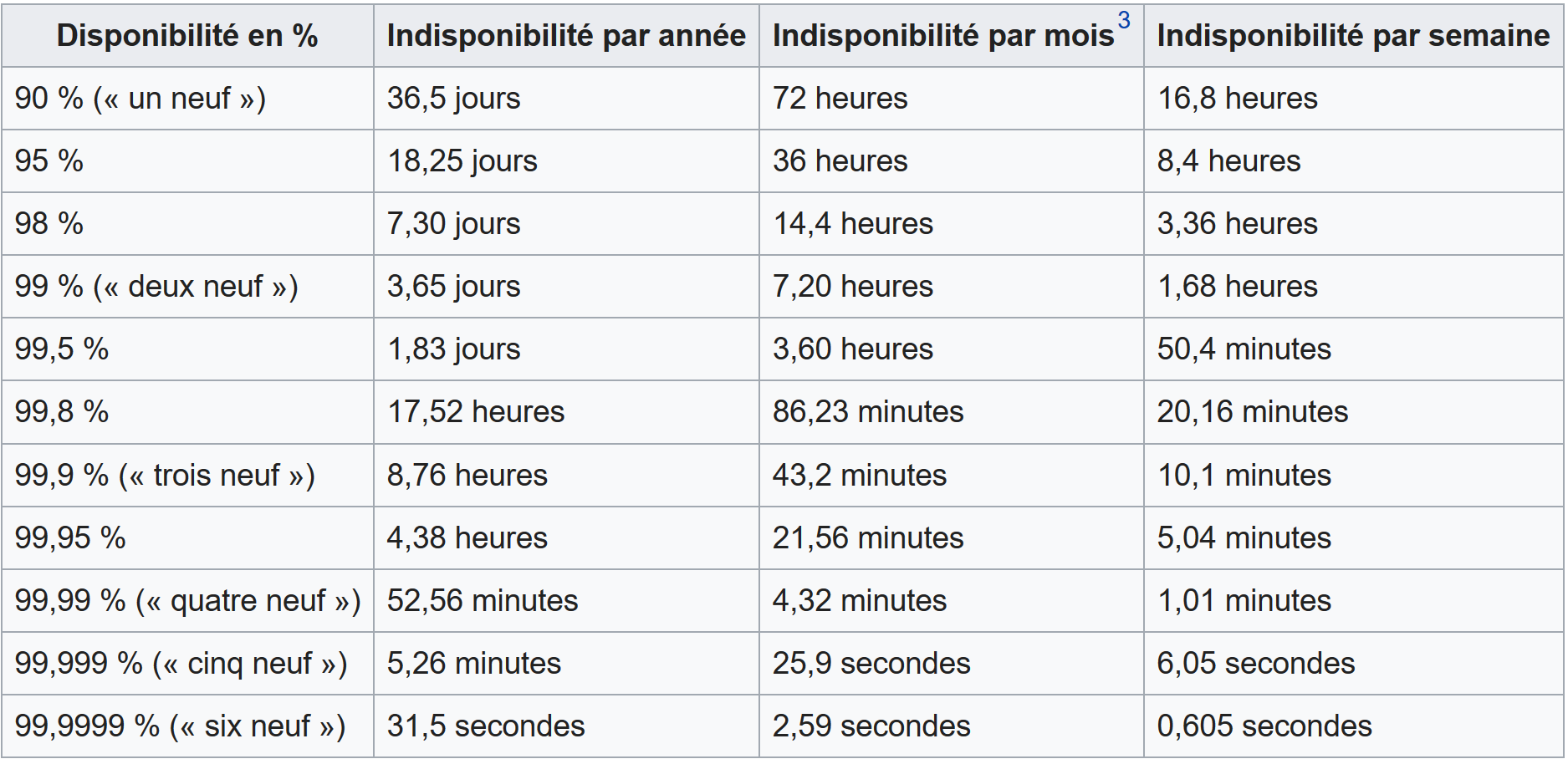
Mesures de disponibilité
désigne la capacité d’un produit à s’adapter à un changement d’ordre de grandeur de la demande (montée en charge), en particulier sa capacité à maintenir ses fonctionnalités et ses performances en cas de forte demande
assure l’accès à ses services en cas de sinistre.
La continuité de services a pour objectif comme son nom l’indique d’assurer l’utilisation constante des services IT de l’entreprise et de prévoir la reprise en cas de sinistre, l’arrêt d’activité étant critique pour l’entreprise et l’informatique étant aujourd’hui au centre de tous les processus, il est nécessaire d’assurer comme pour l’électricité son fonctionnement en continu. Le budget attribué aux stratégies mises en place pour assurer la continuité de l’activité sont proportionnelles à la perte de chiffre d’affaires qu’engendrerai une cessation d’activité.
La continuité de services (CdS ) concerne différents périmètres. On peut assurer la CdS des serveurs web, avec des serveurs redondants et équilibrant la charge, on peut le faire sur tout types de services, DHCP, Active Directory, firewall. Selon les moyens différentes options peuvent aussi être mises en place comme des sites distants, des solutions de télétravail, l’accueil dans bureaux attribués dans des sociétés de sécurité.
est à la fois le nom d’un concept, d’une procédure et du document qui la décrit. Il s’agit de redémarrer l’activité le plus rapidement possible avec le minimum de perte de données.
Pour chaque élément du SI, deux indicateurs de temps sont définis, permettant ensuite de choisir la solution technique la plus adaptée aux besoins de l’entreprise.
D’une manière générale, plus une solution permet de redémarrer rapidement une activité plus elle est coûteuse.
Pour établir un plan de continuité de services le ministère de l’éducation propose un excellent document d’aide à sa rédaction.
Dans des périmètres plus restreint on assure la continuité de services en les répartissant sur des hôtes distincts et en établissant des liens redondants et en assurant de la haute disponibilité on assure aussi de la continuité de services.
La disponibilité et le load balancing repose principalement sur la redondance.
La redondance se rapporte à la qualité ou à l’état d’être en surnombre, par rapport à la logique. Ce qui peut avoir la connotation négative de superflu, mais aussi un sens positif quand cette redondance est voulue afin de prévenir un dysfonctionnement.
Tous les services serveurs peuvent être redondés, voir équilibrés de même que tous les équipements actifs. Les protocoles sont adaptés aux contraintes des matériels et des systèmes.
Au sein des Centre de données, la redondance est mise en place pour assurer que les services de base et les systèmes auront des doublons (équipement, liaisons, alimentation et chemins, données, logiciels…).
L’organisme Uptime Institute a défini une certification internationalement reconnue des centres de traitement de données en quatre catégories, appelées « Tier »:
L’infrastructure Tier I inclut un espace IT dédié aux installations TI; un ASSC (UPS); un Groupe électrogène avec au moins 12 heures d’autonomie en carburant sur site57.
L’infrastructure Tier II inclut le requis pour le Tier I plus des équipements redondants57.
L’infrastructure Tier III inclut le requis pour le Tier II plus toutes les canalisations et câbles redondants57.
(en anglais : load balancing) est un ensemble de techniques permettant de distribuer une charge de travail entre différents ordinateurs d’un groupe pour assurer sa haute disponibilité.
Ces techniques permettent à la fois de répondre à une charge trop importante d’un service en la répartissant sur plusieurs serveurs, et de réduire l’indisponibilité potentielle de ce service que pourrait provoquer la panne logicielle ou matérielle d’un unique serveur.
La répartition de charge est issue de la recherche dans le domaine des ordinateurs parallèles.
L’architecture la plus courante est constituée de plusieurs répartiteurs de charge (genres de routeurs dédiés à cette tâche), un principal, et un ou plusieurs de secours pouvant prendre le relais, et d’une collection d’ordinateurs similaires effectuant les calculs. On peut appeler cet ensemble de serveurs une ferme de serveurs (anglais server farm) ou de façon plus générique, une grappe de serveurs (anglais server cluster). On parle encore de server pool (littéralement, « groupe de serveurs »).
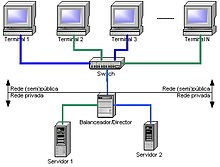
Sur les répartiteurs de charge les plus courants, on peut pondérer la charge de chaque serveur indépendamment. Cela est utile lorsque, par exemple, on veut mettre, à la suite d’un pic ponctuel de charge, un serveur de puissance différente dans la grappe pour alléger sa surcharge. On peut ainsi y ajouter un serveur moins puissant, si cela suffit, ou un serveur plus puissant en adaptant le poids.
Il est généralement également possible de choisir entre plusieurs algorithmes d’ordonnancement :
Il y a deux façons de router les paquets, lors des requêtes :
Bien évidement il faut commencer par avoir au moins une sauvegarde !
La 1ere technique est le Round Robin ou Répartition de charges via DNS
La technique de l’adresse Ip virtuelle est extrêmement utilisée, aussi bien pour les routeurs que pour les terminaux serveurs.
Ainsi on utilisera HSRP sur les routeurs Cisco, VRRP sur les firewalls par exemple. Ipfire avec keepalived et VRRP
On utilisera aussi des services comme heartbeat, keepalived, Haproxy, TS Broker pour gérer la répartition ou l’équilibrage de charges.
A lire aussi le cluster chez Windows
Active Directory redondance des serveurs
Mais aussi DHCP, Terminal serveurs,
On a déjà installé et paramétrer un parefeu Ipfire. Mais avoir un pare feu qui fait éventuellement proxy c’est bien, en avoir un 2ieme redondant c’est mieux.
Aussi ce petit article montre comment facilement et rapidement mettre en place de la redondance avec 2 Ipfire.
Pour info :
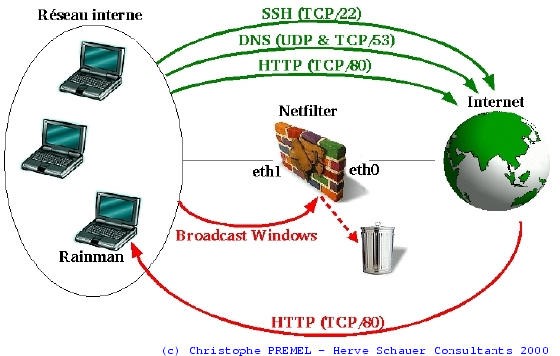 C’est le principe des clés sur les portes, on ne laisse pas entrer n’importe qui à l’intérieur. Seules réponses à des demandent de connexions venant de l’intérieur (voir TCP) sont autorisés. Le paramétrage permet aussi de choisir ce qui sort. Cependant la fonction de filtrage pour les utilisateurs est plus effectuée par la fonction de proxy.
C’est le principe des clés sur les portes, on ne laisse pas entrer n’importe qui à l’intérieur. Seules réponses à des demandent de connexions venant de l’intérieur (voir TCP) sont autorisés. Le paramétrage permet aussi de choisir ce qui sort. Cependant la fonction de filtrage pour les utilisateurs est plus effectuée par la fonction de proxy.
Juridiquement, l’entreprise doit en effet se positionner face à des comportements liés aux menaces internes : le téléchargement de contenus musicaux et/ou pédophiles et le téléchargement de contenu avec un ordinateur appartenant à l’entreprise. Celle-ci doit faire face aux menaces externes via l’infection malicieuse (virus) et la fuite d’information (documents confidentiels, bases de données).
L’administrateur doit donc être en mesure de différencier les sites à risques pour l’utilisateur et par conséquence pour l’entreprise et veiller aux transferts de contenus illicites car l’objectif des pirates est clairement défini : inciter les utilisateurs à se connecter sur un site infecté via des liens corrompus ou des scripts intégrés (Malware, Drive-by-Download, Phishing, Pharming, Spam, Botnet, …) pour récupérer des informations « monnayables » (Spyware, Trojan, …).
Le proxy permet de répondre en partie à ces problématiques en assurant une première barrière de protection avec des fonctionnalités de filtrage avancé des URL via des politiques de blocage des sites web corrompus connus. L’ensemble des sites est ainsi regroupé par classes pour permettre aux entreprises de bloquer les sites malveillants aux contenus dangereux.
Un nom de domaine est un nom de marque, d’entreprise, de famille, relié à un numéro internet , l’adresse IP, par le biais d’un annuaire international appelé DNS. Il permet d’accéder à un site, à un adresse mail en tapant simplement le nom sans avoir à connaitre le numéro qui sera composé. Imaginez un système téléphonique ou vous n’auriez qu’à connaitre le nom de votre interlocuteur et ne pas avoir à composer son numéro de téléphone, ou vous n’auriez aucune recherche à faire si le numéro à changer ! DNS c’est ce système pour les adresses des machines sur Internet !
L’accès distant est inhérent au réseau. Les débuts de l’informatique se faisait via des terminaux, c’est une des premières application en réseau, utilisée pour travailler sur les serveurs et gérer les systèmes distants. . Avec les « PC » (personal computer), les ressources se sont déportés vers les ressources et l’accès distant à évoluer vers l’assistance des utilisateurs. Aujourd’hui, les ressources ce sont recentralisées et avec le cloud tout le monde est utilisateur de l’accès distant. Avec la virtualisation, le système évolue et on met aujourd’hui à disposition des vms via des accès distants, c’est même le fond de commerce d’OVH.
Cependant on parlera ici plus de l’accès distant lorsque l’on utilise des applications spécifiques afin soit de
Dans la suite de ce document vous trouverez quelques explications complémentaires sur les protocoles et les outils d’accès distant et les manipulation a faire pour prendre la main à distance sur tous types de systèmes, serveurs, clients, Linux, Windows.