Supervision
« Surveillance du bon fonctionnement d’un système ou d’une activité –
« Permet de surveiller, rapporter et alerter les fonctionnements normaux et anormaux des systèmes informatiques ».
La surveillance de bout en bout du système d’information est indispensable; actuellement toute l’activité économique des sociétés reposent sur la stabilité et l’interconnexion des systèmes d’informations.
SNMP est un protocole de supervision implanté sur les équipements réseaux administrables qui est à la base de la surveillance d’un réseau. Il faut comprendre ce protocole avant de se lancer dans les outils de supervision :
- PRTG, un outil extrêmement simple et efficace de supervision Supervision avec Prtg
- Pour utiliser des OID, les importer en librairie et gèrer un switch Cisco SF300 avec SNMP et PRTG c’est ici Supervision Switch S 300
- Pour débuter sous Eyes of Network, un outil a base de Nagios c’est là Supervision EON
L’accroissement de la taille d’un réseau géré impose au mieux l’augmentation des capacités de traitement des systèmes sur lesquels sont installées les plates-formes de gestion ainsi que l’augmentation des capacités de transfert des données, et le changement des systèmes existants pour des systèmes plus puissants.
Il faut pouvoir agir efficacement et facilement pour prévenir et guérir toute défaillance, tant du point de vue de l’accès aux données, que de leur stockage et de leur transfert.
Il faut distinguer la supervision du réseau, des applications, du stockage, des bases de données, des serveurs, la supervision Web et la gestion des processus métiers.
Il existe de nombreux produits permettant de faire de la supervision et le monde du libre est particulièrement bien représenté : Nagios est en effet un produit libre et très utilisé (sous ces différentes formes : FAN, EON, Shinken).
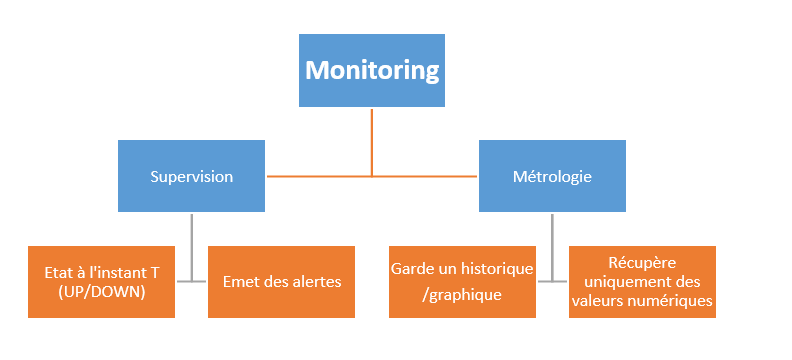
« Le monitoring, désigne le fait de « surveiller » , ou « garder un oeil sur » . Cependant, le fait de surveiller quelque chose revient à connaître sont état actuel mais aussi l’historique de ses états passés, par l’intermédiaire de valeurs (UP/DOWN) et de données chiffrées (des pourcentages par exemple). C’est ici que l’on retrouve une distinction entre deux notions que sont la supervision et la métrologie.
La métrologie, dans laquelle on retrouve la notion de mètre/métrique, est le fait d’obtenir, de garder et de tracer la valeur numérique d’une charge. Par exemple le pourcentage de CPU utilisé sur un serveur, le nombre de personnes connectées sur une site web, le trafic sortant et entrant sur un switch.
La métrologie est donc le fait de récupérer la charge (chiffrée), permettant de tracer son évolution dans le temps. Elle est donc caractérisée non pas par le fait de récupérer une valeur à l’instant T, mais de pouvoir afficher et tracer l’évolution d’une charge, construite par un ensemble de métrique récupérées dans le temps.
La supervision, en revanche, est le fait de récupérer l’état d’un service à l’instant T. la supervision vise à répondre à la question « Le service est-il joignable ? » . Au sens strict du terme, aucune valeur numérique n’entre en compte, et l’aspect historique de charge ne fait donc pas partie de la supervision. L’exemple le plus frappant est Nagios qui, par défaut, ne possède aucune fonctionnalité permettant de tracer des graphiques ou obtenir l’historique de la charge d’un service/serveur. Une « extension » de la supervision porte sur le fait de récupérer une valeur chiffrée comme une charge mémoire et de lui appliquer un seuil d’alerte.
Avec le temps, supervision et métrologie tendent à complètement se confondre dans les solutions proposées. Ainsi, lorsque l’on cherche à récupérer une information, on parle alors de monitoring. On est maintenant capable d’appliquer de la supervision sur la métrologie, pour faire plus claire, on va appliquer des alertes sur des seuils de charge. Certains produits permettent d’ailleurs de fusionner totalement métrologie et supervision dans le sens où, si la charge (par exemple CPU) est très différente de l’historique habituel des 7 derniers jours, alors on envoie une alerte. »
(https://www.it-connect.fr/monitoring-supervision-et-metrologie/)
SNMP
SNMP est le 1er protocole de supervision. actuellement il en est a sa version 3.
Il repose sur les éléments suivants :
- Une console ou centre de supervision, qui centralise toutes les informations, le SNMP manager.
- Des équipements sur lesquels sont installés des agents SNMP qui enregistrent et envoient des informations à la console
- Des MIB, bases de données qui contiennent les valeurs interrogeables des équipements

MN (Managed Node)
Les équipements sont des nœuds administrables – et peuvent être des serveurs, des routeurs, des switchs (administrables bien sur).
- Sous Windows, SNMP n’est pas activé par défaut, car Microsoft utilise un système propriétaire WMI -Windows Management Information, cependant il est très simple de l’activer via les fonctionnalités.
L’agent sur le nœud stocke ces informations dans une base de données appelée
MIB (Management Information Base)
Cette base contient les informations sur les composantes de la station ou du routeur,
ex : uptime, configuration du routage, état du disque et du port série, nombre de paquets reçus et envoyées, combien de paquets erronés reçus,
Ces informations qui sont demandées par la station de gestion afin d’effectuer son travail.
Ce peut-être aussi l’agent qui envoie une alerte à la console –Trap.
exemple : espace disque libre inférieur à 20%. Le seuil de l’alerte a été paramétrer préalablement par l’administrateur.
Petit exemple drôle de supervision pris sur un site expliquant bien SNMP (http://superwebcrawler.fr/dokuwiki/doku.php?id=supervision:courssnmp)

Les MIBS sont soient publiques soit privées. En effet ils existent des MIBs spécifiques pour permettre à des constructeurs de permettre d’interroger plus spécifiquement chacun de leur matériel. Si on gère un switch Cisco SF300 par exemple, on ira télécharger la MIB spécifique (Fichier MIB SF300).
Extension de la MIB
Au bout d’un moment, les variables choisies pour la MIB (puis la MIB2) se sont avérées insuffisantes pour plusieurs applications. On va donc trouver deux autres types de MIB que sont les Private MIB et les MIB R-MON (Remote network MONitoring).
Les Private MIB, représentées en 1.3.6.1.4 dans la classification SMI (voir ci-dessous), permettent aux entreprises de rajouter des variables pour une implémentation particulière des agents SNMP. Cela leur permet d’ajouter de nouvelles variables en fonction des applications qu’elles veulent développer.
Les MIB R-MON permettent par exemple de placer des agents SNMP sur le trafic. L’administrateur pourra l’interroger pour avoir des informations sur les collisions, les débits à un endroit précis.

Vue du trafic sur 2 ports d’un switch grâce à R-Mon
OID (Object identifier)
Ce sont les Variables sous la forme 1.3.6.etc…Chaque variable contient une valeur (i.e le statut d’un port, sa vitesse…). Un manager MIB peut interroger une variable et en ressortir sa valeur. (Cf Mib, Snmp, Rmon, Snmp).

Afin de consulter les OID d’un élément on peut aussi simplement taper (depuis un Linux) :
snmpwalk -v version_snmp -c communauté adresse_ip_equipement OID
Exemple en envoyant le résultat de la commande dans un fichier : snmpwalk -v 2c -c public 192.168.1.1. 1.3.6 > list_oid
extrait du fichier :

Un excellent outil, plus convivial pour explorer les MIBS est OIDVIEW
Voilà une vue de ce que l’on peut obtenir avec cet outil

SMI (Structure of Management Information)
Pour se retrouver dans la foule d’informations proposées par chaque agent, on a défini une structure particulière pour les informations, appelée SMI. Chaque information de la MIB peut être retrouvée soit à partir de son nom de variable, soit à partir d’un arbre de classification. Cela revient à parcourir des sous-dossiers et dossiers d’un disque dur…
Supposons que vous souhaitiez consulter la variable System d’un hôte, vous pouvez lui demander la variable ayant pour OID (Object IDentification) 1.3.6.1.2.1.1… correspondant à l’arborescence de la variable (ISO, Identified Organization, dod, Internet, Management, MIB2, System).
Voici ci dessous un exemple d’arbre MIB :

Cela peut paraître assez contraignant à première vue, mais le nombre de variables étant important, on ne peut se souvenir de chaque nom. Par contre, il existe de nombreux logiciels permettant d’explorer la MIB de façon conviviale, en utilisant cette classification.
Ensuite on utilisera un explorateur de MIB pour visualiser les informations à récupérer, car ils existent une multitude d’informations possibles.
(par exemple les vlans)

Communauté
L’accès aux informations des MIBs est contrôlé par un mécanisme simple utilisant des noms de communautés. Un nom de communauté peut être assimilé à un mot de passe connu par l’agent et utilisé par le manageur pour se faire reconnaître. Les noms de communautés sont configurés sur l’agent et autorisent trois types d’accès sur les variables de la MIB gérée par l’agent :
- Pas d’accès
- Read-Only
- Read-Write.

Les différents types d’opérations
Deux situations sont possibles pour les échanges de données. Soit l’administrateur réseau demande une information à un agent et obtient une réponse, soit l’agent envoie de lui-même une alarme (trap) à l’administrateur lorsqu’un événement particulier arrive sur le réseau.
Il est donc possible que l’agent prévienne l’administrateur de son propre chef si un incident survient.
Il existe quatre types de requêtes :
- GetRequest : permet d’obtenir une variable.
- GetNextRequest : permet d’obtenir la variable suivante (si existante, sinon retour d’erreur).
- GetBulk : » permet la recherche d’un ensemble de variables regroupées. «
- SetRequest : permet de modifier la valeur d’une variable.
Puis, les réponses :
- GetResponse : permet à l’agent de retourner la réponse au NMS.
- NoSuchObject : informe le NMS que la variable n’est pas disponible.
Les types d’erreurs sont les suivants : NoAccess, WrongLenght, WrongValue, WeongType, WrongEncoding, NoCreatio, NoWritable et AuthorisationError.

Alertes (traps)
sont ColdStart, WarmStart, LinkUP et AuthentificationFailure.
Le protocole SNMP prévoit la possibilité pour l’agent client installé sur l’équipement, lorsque rencontre un événement prédéfini, d’envoyer une notification (appelée trap) au serveur de supervision pour l’en avertir.
Exemples d’évènements prédéfinis : un disque qui a moins de 10 % d’espace libre, le trafic de diffusion qui dépasse 40 % sur un port de commutateur.
Le signal envoyé au serveur de supervision contient plusieurs attributs dont :
L’adresse de l’équipement qui a envoyé l’information.
L’OID racine (Object Identifier) correspond à l’identifiant du message reçu.
Le message envoyé au travers du trap SNMP qui correspond à un ensemble de paramètres.
Afin de pouvoir interpréter l’évènement reçu, le serveur de supervision doit posséder dans sa configuration les éléments nécessaires pour traduire l’évènement. Pour cela, il doit disposer d’une base de données contenant les OID ainsi que leurs descriptions, appelée MIB (Management Information Base).
Format des messages

Que surveiller
Sur un agent
PRTG, qui est un outil de supervision, donne un aperçu des type d’informations que l’on peut surveiller

Les principaux indicateurs sont
En matière de supervision réseau
- la bande passante,
- la variation du temps de latence des paquets,
- la perte de paquets,
- la perception applicative vue de l’utilisateur.
Ils permettent la visibilité sur les flux qui transitent sur un réseau d’entreprise
- mesure volumétrique des flux en temps réel,
- mesure de la charge en télécom des serveurs,
- visibilité des flux d’impression et de leur proportion en bande passante,
- mesure des flux inter-serveur (notamment si les serveurs ne sont pas physiquement au même endroit).
- visibilité réelle des répartitions de charge.
Les flux peuvent être aussi découpé par implantation géographique des réseaux (VPN, MPLS, Internet, CPL, etc), et par entité logique (WiFi, Interlan, VoIP, departement, application, mainframe, etc).
En matière de supervision des serveurs
Les indicateurs concernent :
- la vitesse de lecture et d’écriture des disques,
- la capacité libre disponible,
- le taux moyen d’occupation des supports
- la dispersion des informations.
En matière de sécurité
La supervision ne se substitue pas à un antivirus ou un IPS, mais permet de gérer une sécurité plus comportementale lié à un dysfonctionnement ou à un flux lié à un problème de sécurité.
Par exemple :
- Détection des flux illégitimes (P2P, Chat, podcast, jeux en ligne, streaming video, streaming audio, ToIP non autorisée – skype, webmail, etc.).
Détection des sites Internet consultés par les utilisateurs pouvant mettre en cause la responsabilité de l’établissement (sites de piratages, sites pornographiques, sites de P2P,etc.). - Détection des flux malvaillants, détection des connexions cryptées non autorisées (HTTPS, SSL, SSH, LDAPS, P2P en HTTPS, etc
- Visibilité d’une consommation anormale de bande passante, de flux entre deux zones du réseau non autorisées à le faire et de flux « non conforme à l’usage commun de l’établissement ».
- Analyse possible d’un spyware qui émet des requêtes régulières vers des sites non autorisés, concurrents, ou référencés comme étant des sites « sensibles »
- Détection de machines n’étant pas dans le plan d’adressage IP de l’établissement.
- Détection des requêtes SNMP (supervision) illégitimes (émanant de stations ou de machines non autorisées à le faire) et détection des scans réseau (identification du contributeur).
En matière de performances
La supervision aide à la gestion globale des performances, pour garantir le niveau de service –QOS-. Certains éditeurs jouent sur une certaine ambigüité entre la supervision et la gestion de la qualité de services pour vendre leur produit.
Mais il s’agit plutôt d’outils complémentaires car la qualité de service ne pourra être évaluée sans un outil de supervision puisqu’il s’agit de mesurer :
- La disponibilité du service,
- Le temps d’attente pour obtenir le service,
- L’intégrité des données.
Les indicateurs de QOS se recoupent avec ceux de supervision de réseau, cependant, ils permettent une approche beaucoup plus qualitative
Indicateurs QOS
- La qualité de service au niveau applicatif
Désigne la qualité perçue par l’utilisateur final. Les critères d’appréciation sont donc plutôt subjectifs, même si certains événements tels que les pannes ou les erreurs sont directement perceptibles et peuvent être évalués de manière rigoureuse. - La qualité de service au niveau du transport
Désigne la qualité de service d’un point A à un point B (notion de routing), compte tenu des aléas dus à la multitude des acteurs impliqués (au niveau des opérateurs, d’un réseau métropolitain (MAN), d’un fournisseur d’accès…).
- La qualité de service de réseau
Au sein d’un réseau donné, la qualité de service est évaluée en fonction des différents équipements qui le composent, des règles qui y ont été définies, du trafic qui y circule, etc. - La qualité de service « de bout en bout »
Derrière cette expression, qui signifie que la qualité de service est théoriquement la même d’un bout à l’autre d’un réseau, on trouve une multitude de situations, notamment conditionnées par la pluralité des opérateurs et des matériels présents, ainsi que des capacités réseau et des politiques de qualité de service en place. Certains noeuds de redistribution peuvent dans ce cas être sources d’engorgement. - La perte de paquets
Correspond aux octets perdus lors de la transmission des paquets. S’exprime en taux de perte. Plutôt rare. - Le délai de transit (latence)
C’est le délai de traversée du réseau, d’un bout à l’autre, par un paquet. Les différentes applications présentes sur ce réseau n’auront pas le même degré d’exigence en fonction de leur nature : faible, s’il s’agit d’une messagerie électronique ou de fichiers échangés, ce degré d’exigence sera fort s’il s’agit de donnés « voix ». La latence dépend du temps de propagation (fonction du type de média de transmission), du temps de traitement (fonction du nombre d’équipements traversés) et de la taille des paquets (temps de sérialisation). - La gigue
Désigne les variations de latence des paquets. La présence de gigue dans les flux peut provenir des changements d’intensité de trafic sur les liens de sorties des commutateurs. Plus globalement, elle dépend du volume de trafic et du nombre d’équipements sur le réseau. - La bande passante
Il existe deux modes de disponibilité de la bande passante, en fonction du type de besoin exprimé par l’application. Le mode « burst » est un mode immédiat, qui monopolise toute la bande passante disponible (lors d’un transfert de fichier par exemple). Le mode « stream » est un mode constant, plus adapté aux fonctions audio/vidéo ou aux applications interactives.
- Intérieur du réseau
Afin d’arbitrer entre les modes « burst » et « streaming » précédemment cités, une gestion du trafic peut soit être installée au sein du réseau, soit à ses extrémités. S’il s’agit de l’intérieur du réseau, les noeuds de ce réseau opèrent alors comme autant d’éléments de classification et de priorisation des paquets qui y circulent. - Extérieur du réseau
Si, en revanche, le dispositif se trouve à l’extérieur, les équipements constituant le réseau se trouvent déchargés de toute QoS. Deux mécanismes sont alors à l’oeuvre : le contrôle de débit TCP, qui modifie le débit des applications TCP en fonction des conditions de charge du réseau et du niveau de priorité des applications, et la gestion des files d’attente personnalisées, qui affecte les flux entrants
Aide à la décision
La supervision fournit également la direction informatique en indicateurs objectifs, remontant les données qualitatives ou quantitatives relatives à la gestion des ressources informatiques. Ces données permettent également de mesurer les effets de l’application de nouvelles mesures comme le changement d’un logiciel, la priorisation de flux IP ou l’optimisation de code. Enfin, dans le cadre de contrats de prestation de services, la supervision s’avère indispensable pour mesurer l’efficacité du prestataire et remonter d’éventuels problèmes.
Que ce soit sur Nagios (FAN ou EON) ou sur une appli sous Windows (PRTG ou SpiceWork), il y a deux grands principes, les templates et les dépendances qui permettent de facilité le monitoring des équipements.
Templates
Pour mettre en place une supervision on commence généralement par scanner le réseau
- On affecte aux éléments scannés des templates selon leur type

Les templates ou modèles permettent de gagner en efficacité , ce sont les modèles de commandes à exécuter sur un type d’équipement.

Dépendances
Dans un réseau, les équipements sont inter-dépendants, il faut refléter cette dépendances dans la console de supervision.
On définit un système de parent-enfant

et généralement on le représente graphiquement.
s’il n’y a pas de gestion des dépendances et si un élément tombe en panne :
tous ceux situés en aval ont l’air d’être en panne et l’administrateur et/ou le(s) technicien(s) recevront des alertes incorrectes et inutiles ;
graphiquement on ne peut pas voir d’où vient réellement la panne.
Pour integrer du code PHP https://www.php.net/manual/fr/snmp.installation.php
Pour ceux qui voudraient créer leur plugin https://www.it-connect.fr/creer-son-plugin-de-supervision/